
Intro
이전 포스트들을 통해 Handcrafted Optical Flow 기법들에 대해 알아보았습니다. 이제는 Deep Learning을 통해 Optical Flow를 구하는 연구들에 대해 다룰 예정입니다. 그 시작은 ICCV 2015에서 발표된 FlowNet이 끊었습니다. FlowNet 이전에는 하드웨어와 Deep Learning에 대한 연구가 부족하였고, 가장 중요한 포인트는 학습에 필요한 Optical Flow Groundtruth 데이터셋의 부족이었습니다. 이번 포스트에서는 이런 한계를 FlowNet이 어떻게 극복했는지 살펴보겠습니다.
Abstract
FlowNet은 Supervised Learning 방식의 학습을 통해 Optical Flow를 구하는 알고리즘입니다. Supervised Learning을 위해 Optical Flow 추정의 한계였던 데이터셋 부족 문제를 나름의 방식으로 돌파했습니다. 이 방식은 이후 Optical Flow 연구에 큰 기여를 했고, Dataset 부분에서 다루겠습니다.
FlowNet은 CNN의 End-to-End 방식의 학습 방법입니다. Optical Flow는 입력이 두 이미지가 되기 때문에 End-to-End 학습을 위해 correlation layer를 도입해 픽셀 단위의 localization을 수행했습니다.
전통적인 Handcrafted 방식의 Optical Flow 추정 기법인 Lucas-Kanade, Horn-Schunck 등은 별도의 학습 없이 알고리즘의 파라미터를 매뉴얼 하게 설정합니다. 따라서 사용하는 엔지니어의 숙련도와 이해도에 따라 성능 차이가 발생합니다. 하지만 Deep Learning 기법을 사용한 FlowNet은 사람의 개입을 최소화해 이런 문제를 해결할 수 있습니다.
Dataset
Optical Flow의 Groundtruth를 구하는 것은 꽤나 골치아픈 문제입니다. 기존의 알고리즘들을 이용해 구하는 방법은 앞서 언급했듯이 편차가 발생합니다. 그렇다고 매뉴얼 하게 데이터를 생성하게 되면 학습에 적합하지 않은 형태가 될 수 있습니다.
FlowNet은 이런 문제를 Flying Chairs라는 데이터셋을 직접 만들어 해결했습니다. Flying Chairs는 Flicker DB에 3D Chairs 이미지를 합성해 만든 데이터셋입니다. 즉, 현실적으로 만들기 어려운 학습 데이터셋을 리얼 데이터셋이 아닌 합성 데이터셋을 만들어 학습을 진행했습니다.

FlowNet에서 제안한 Flying Chairs 데이터셋은 단순히 아이디어에 그치지 않고 실제로 Optical Flow를 구하는데 성공합니다. 이는 합성 영상으로 학습한 네트워크를 현실 영상에 적용이 가능함을 보여주었습니다. 이후에 Flying Chairs 데이터셋을 비롯한 여러 합성 데이터셋은 Read data가 부족한 Optical Flow 분야의 다른 연구에서도 학습을 위해 많이 사용되었습니다.
FlowNet
두 프레임 사이의 Optical Flow를 구하기 위해서는 필연적으로 2개의 input을 가집니다. 2개의 입력값을 받으며 End-to-End 형식으로 학습하기 위해 FlowNet은 두 가지 방법을 제안합니다. 우선 아래 이미지는 FlowNet의 기본적인 Concept image입니다.
CNN Architecture를 End-to-End 방식으로 학습시켜 Optical Flow를 계산합니다. Network Architecture에 따라 Generic Architecture인 FlowNetS 모델이 있고, 두 이미지의 Feature Map의 상관관계를 이용한 FlowNetC가 있습니다. S, C는 각각 Simple과 Corr(Correlation)의 의미를 가집니다.
또한, 계산량을 고려해 현실적인 학습을 하기 위해 Pooling layer를 사용합니다. Pooling layer를 사용하며 넓은 영역의 정보를 합치는 효과를 주게 됩니다. 이는 개인적으로 전통적인 Optical Flow 기법에서도 사용하는 Coarse-to-Fine 기법과 유사하다고 생각합니다.
Coarse-to-Fine 기법과 마찬가지로 줄어든 해상도를 원복하는 과정이 필요한데 FlowNet에서는 이 과정을 Refinement layer에서 수행하게 됩니다. 이로서 입력 이미지와 같은 해상도를 갖는 픽셀 단위의 Flow Map을 획득하게 되며, CNN based End-to-End Model이 완성됩니다.
Network Architecture
FlowNet은 아래 그림과 같이 FlowNetSimple(FlowNetS)와 FlowNetCorr(FlowNetC), 두 가지 Architecture를 제안합니다.

- FlowNetSimple
FlowNetSimple은 이름에서 알 수 있듯이 좀 더 간단한 형태의 네트워크입니다. 입력 채널 수가 6인 것을 통해 Optical Flow 계산에 필요한 두 이미지를 concat 해서 input 했다는 것을 알 수 있습니다. 이후의 네트워크 형태는 전통적인 CNN Architecture 구조를 따릅니다. Supervised Learning으로 학습시켜 네트워크 스스로 Optical Flow 추출 방법을 결정할 수 있게 합니다.
- FlowNetCorr
FlowNetCorr은 좀 더 복잡한 구조를 띄고 있습니다. 입력 채널 수가 3으로 줄어든 것에서 알 수 있듯이 concat 과정이 없습니다. 대신 입력단을 나누어 두 이미지에 대한 입력을 받습니다. FlowNetCorr의 특징인 Correlation layer(corr)에 오기 전을 입력단이라고 했을 때, 두 입력단은 완전히 동일한 구조를 갖습니다. 각 입력단을 거치며 두 이미지에서 각각의 Feature Map을 추출해 Correlation layer를 통해 하나로 합치는 구조입니다. 이 Feature Map에 대해 논문에서는 meaningful representations of the two images라고 언급하고 있습니다.
여기서 의문인 것은 Correlation layer를 통해 하나로 합치는 방법입니다. 이미지가 아닌 Feature Extraction을 통해 얻은 Feature Map을 input으로 어떻게 correlation을 갖는 걸까요? 아래 Detail 부분에서 그 방법을 살펴보겠습니다.
Details
FlowNet은 대부분 일반적인 CNN Architecture 구조를 띄고 있어 이해가 어렵지 않습니다. 하지만 Correlation layer는 별도의 설명이 필요해 보입니다. 또한 보통의 CNN Architecture에서는 볼 수 없는 Refinement layer에 대한 부연 설명도 진행해 보겠습니다.
- Correlation layer
논문에서는 Correlation 과정을 아래의 식으로 표현합니다.

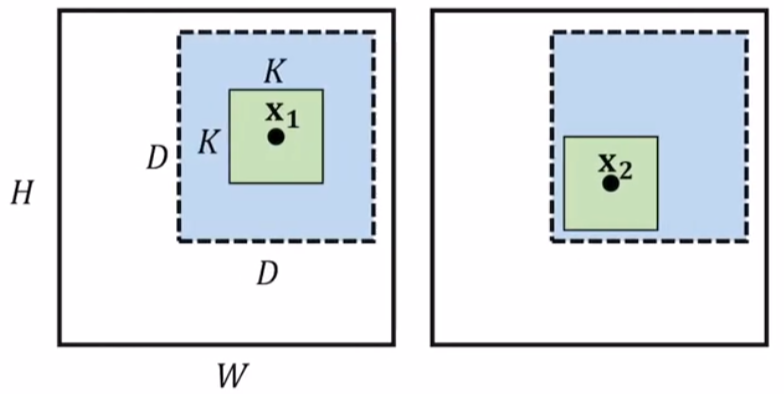
우선 Correlation을 위해 d, D, k, K 를 정의해야 합니다. 이 과정은 글로 표현하기 복잡하니 생략하고 Reference에 논문 링크를 남길 테니 참고 바랍니다. 영역을 정의한 후 벡터 단위로 Correlation 연산을 살펴보면 x1 위치의 벡터와 x2 위치의 벡터의 내적으로 볼 수 있습니다. 쉽게 표현하자면 미리 정의한 patch의 원소마다 내적을 한 후 summation을 통해 나온 결괏값을 채널 축으로 쌓는 과정입니다.

위 값의 크기를 갖는 직육면체의 채널 축이 Correlation layer의 output입니다. 아래는 Correlation layer의 이해를 돕기 위한 예시 그림입니다.
- Refinement layer
Refinement layer는 FlowNet의 끝단에 있는 layer입니다. FlowNetS, FlowNetC 둘 다 Refinement layer를 갖고 있습니다. 우선 아래 그림을 통해 구조부터 살펴보겠습니다.
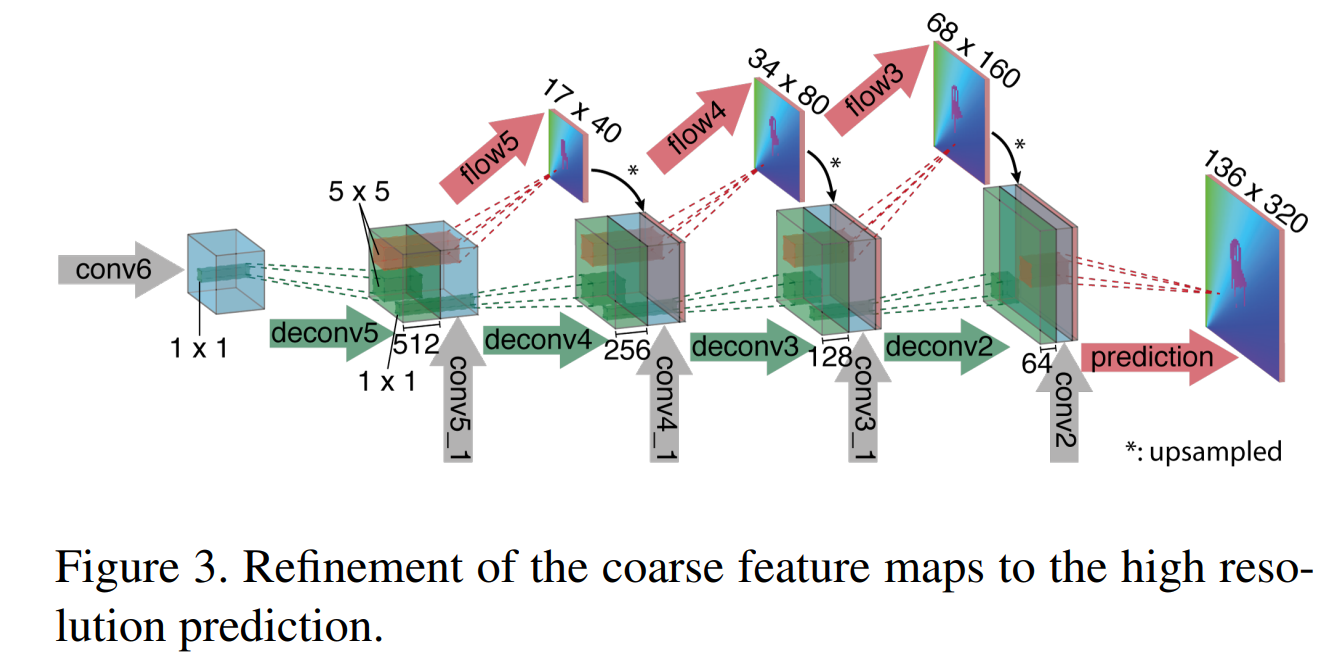
그림에서 알 수 있듯이 Refinement layer는 Upsampling과 Convolution을 반복하는 구조입니다. 또한 중간중간에 보이는 conv5_1, conv4_1와 같이 앞에서 계산된 layer를 concat하는 방식을 사용합니다.
또한 flow5, flow4와 같이 중간 결과값에 대한 Flow Map을 뽑아서 Groundtruth image의 Downsampling 버전과 비교를 해 loss를 계산합니다. Optical Flow는 EPE(End Point Error) Loss를 많이 사용하는데 이는 Estimated와 Groundtruth의 L2 Loss입니다.
Contribution
여태까지 적은 내용만 보면 FlowNet은 Handcrafted 기법의 종말을 가져올 혁신으로 보였습니다. 하지만 놀랍게도 FlowNet의 성능은 기대보다 잘 나오지는 않았습니다.
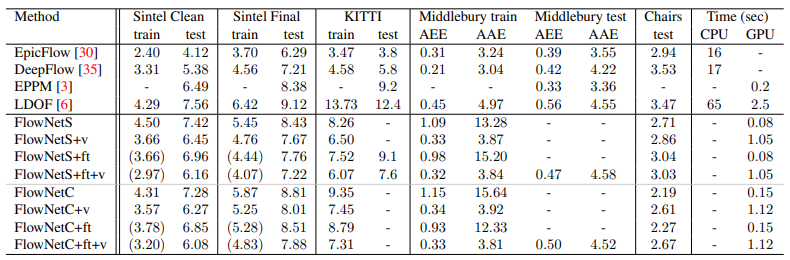
Handcrafted의 정수라고 필자가 개인적으로 생각하는 Epicflow보다 EPE가 더 높고 성능이 안 좋음을 알 수 있습니다. 하지만 그렇다고 FlowNet이 아무 의미가 없냐고 묻는다면 절대 아닙니다. Optical Flow를 위한 최초의 DL 모델인 상징성을 제외하고도 FlowNet은 충분한 Contribution이 있습니다.
- 합성 영상을 이용해도 Real World에서 통하는 학습을 할 수 있음을 확인했습니다.
- 이후 DL을 이용한 Optical Flow 연구에 꼭 필요한 Flying Chairs Dataset을 생성했습니다.
- CPU로만 진행하던 Optical Flow 계산을 GPU 영역으로 끌고와 계산 속도를 크게 향상했습니다.
또한, FlowNet의 성능을 향상한 FlowNet2.0이 CVPR 2017에서 발표됨에 따라 그들의 방향성이 의미 있음을 증명했습니다. 이는 제 졸업 연구를 책임진 고마운 논문입니다. FlowNet2.0은 FlowNet의 모든 걸 계승한다고 말해도 과언이 아닙니다. 따라서 FlowNet에 대한 높은 이해도가 바탕이 되어야 합니다.

Reference
PR-214: FlowNet: Learning Optical Flow with Convolutional Networks
제 PR12 첫번째 발표 논문은 FlowNet이라는 논문입니다. Optical Flow는 비디오의 인접한 Frame에 대하여 각 Pixel이 첫 번째 Frame에서 두 번째 Frame으로 얼마나 이동했는지의 Vector를 모든 위치에 대하여 나
www.slideshare.net
FlowNet: Learning Optical Flow with Convolutional Networks
Convolutional neural networks (CNNs) have recently been very successful in a variety of computer vision tasks, especially on those linked to recognition. Optical flow estimation has not been among the tasks where CNNs were successful. In this paper we cons
arxiv.org
Next
다음 포스트에서는 FlowNet2.0에 대해 다루겠습니다.