
세 줄 요약:
- ORB는 key point detector로 FAST, descriptor로 BRIEF를 각각 개선해 적용했다.
- FAST에서 Rotation & Scale invariance, Multi-scale 개선을 통해 Robustness를 증가시켰다.
- BRIEF의 경우 uncorrelated and high variant 한 pair selection을 통해 feature 품질을 향상했으며, 회전에 대한 보정을 주어 rotation invariance를 개선했다.
Introduction
이전 게시물들을 통해 SLAM Frontend(Visual Odometry)가 무엇인지 다뤘습니다 (이전 게시물들은 Visual Odometry 태그 검색이나, [SLAM/VO] 제목 검색을 통해 보실 수 있습니다). 그중 특히 Feature based VO를 중점으로 다루며, 좋은 feature를 선정하기 위해 필요한 key point와 descriptor를 소개했습니다. 이번 시간에는 Feature Detection and Description 알고리즘 중 하나인 ORB (Oriented FAST and Rotated BRIEF)를 이야기해 볼까 합니다.
ORB란?
2011년에 ORB: an efficient alternative to SIFT or SURF 논문을 통해 처음 소개된 ORB는 현재까지도 real-time task에서 feature extraction을 위해서는 업계 포준처럼 여겨지는 알고리즘입니다. ORB의 정체를 알아보기 위해서는 우선 어떤 카테고리에 속하는 알고리즘인지 알아봐야 합니다. Harris, FAST, GFTT 등이 속한 feature detection 알고리즘일까요? 아니면 BRIEF, LBP 등이 속한 feature descriptor 알고리즘일까요?
정답은 'ORB는 스스로 다 할 수 있어요!'입니다. Feature detection을 통해 key point를 추출하고, descriptor를 계산합니다. 즉, ORB key point와 ORB descriptor 모두를 산출해 ORB feature를 최종 결과물로 내는 알고리즘입니다. 사실 이는 이름에서도 유추할 수 있는데요. Oriented FAST and Rotated BRIEF, 이름에 detector인 FAST와 descriptor인 BRIEF가 모두 들어가 있습니다. 즉, FAST로 key point를 뽑고 BRIEF로 descriptor를 계산할 거라고 광고를 하고 있는 거죠.
그렇다면 ORB는 어떤 알고리즘이라고 해야 할까요? 개인적으로는 Feature Detection and Description 알고리즘, 혹은 Feature Extraction 알고리즘이라고 생각합니다. 다만 논문을 보면 Abstract에서 저자가 다음과 같이 binary descriptor라고 정의 내리고 있으니 Descriptor로 정의 내릴 수도 있습니다 (실제로 Descriptor를 key point를 추출하는 feature detection을 포함하는 개념으로 사용하는 경우가 많습니다).
In this paper, we propose a very fast binary descriptor based on BRIEF, called ORB, which is rotation invariant and resistant to noise.
여기서 굉장히 중요한 포인트가 있는데요. 저자는 ORB의 장점을 rotation invariant와 resistant to noise로 정의했습니다. 이는 기존의 FAST와 BRIEF에서는 볼 수 없던 요소들입니다. 즉, 단순히 FAST와 BRIEF를 결합해 새로운 이름을 붙인 것이 아니라 두 알고리즘을 개선해 새로운 알고리즘을 탄생시킨 것입니다. 각각 Oriented FAST와 Rotated BRIEF로 표현된, 어떻게 보면 FAST 2.0과 BRIEF 2.0에 대해서는 우선 기존의 FAST 1.0과 BRIEF 1.0부터 살펴보고 차근차근 다루겠습니다.
FAST (Features from Accelerated Segment Test)
FAST는 2006년에 machine learning for high-speed corner detection 논문을 통해 처음 소개되었습니다. FAST는 Robotics를 포함해 활용할 수 있는 자원이 적은 환경에서 Real-time task를 수행하고자 제안되었습니다. 그렇기에 적은 연산양과 빠른 속도가 알고리즘의 가장 큰 장점이자 Contribution으로 볼 수 있습니다. FAST는 인접 pixel과 차이가 크면 Corner/Edge 등의 feature point라고 가정해 오로지 밝기 변화에만 집중했습니다. 따라서 이미지의 Grayscale 변화로만 feature를 추출합니다. 알고리즘의 전체적인 흐름은 아래와 같습니다.
- Image($I$) 내 pixel($p$)의 밝기 $I_p$와 Corner를 판정하기 위해나 Threshold($T$) 설정
- $p$ 인접 16개($radius=3$)의 pixel($p'$)들에 대해 아래의 계산을 수행
- $|I_p-I_{p'}|>T$인 $p'$이 $N$개 이상인 경우 corner로 판정
이때 $N$에 따라 FAST-N으로 표기합니다. 아래 Pseudo code를 통해 알고리즘을 좀 더 살펴보도록 하겠습니다.
for pixel in Image:
Image Patch = [16 pixels on a circle, (center = pixel, radius = 3)]
for pixel' in Image Patch:
if |Intensity(pixel) - Intensity(pixel')| > T for consecutive N pixels:
return corner
else:
continue
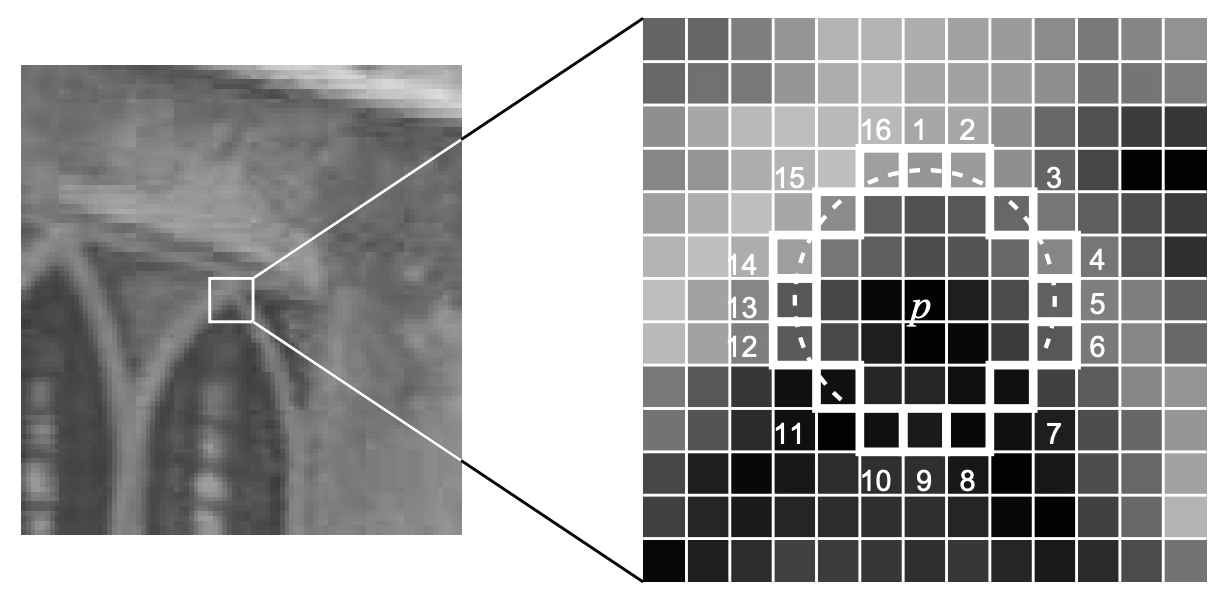
이렇게만 해도 key point 추출을 위해 단순 Intensity 비교만 필요하기에 FAST는 상당히 빠른 속도를 자랑합니다. 하지만 더 빠른 속도와 좀 더 괜찮은 품질의 key point를 위해 FAST는 한 걸음 더 나아갑니다. Key point candidate가 되기 위해서는 반드시 만족해야 하는 조건을 우선적으로 확인해 전체적인 계산량을 줄이고, Corner Clustering을 피하기 위해 Non-maximal Suppression을 적용했습니다.
FAST-12를 예제로 보면, 12개의 연속적인 점에서 FAST 조건을 만족할 가능성이 있는지 보기 위해서는 1, 5, 9, 13번째 pixel을 봐야 합니다. 우선 위 네 개의 점을 확인해 최소 세 점에서 만족하지 않는다면, 이 점이 corner가 될 가능성은 0이 됩니다. 이렇게 빠르게 네 점을 확인해 조건을 만족하지 않는다면, 빠르게 해당 pixel을 건너뛸 수 있습니다.
또한, FAST는 알고리즘이 단순한 만큼 Clustering 문제가 발생하게 됩니다. 이를 피하기 위해 Non-Maximal Suppression(NMS)를 적용합니다. $|I_p-I_{p'}|$의 합을 통해 $p$의 Score $V_p$를 계산합니다. 이를 인접 key point와 비교해 낮은 pixel을 버림으로써 clustering을 회피하려고 노력합니다. 이렇게 빠르고 나름의 정확도를 확보하려고 노력한 FAST지만, 아래와 같은 한계가 존재합니다.
- Feature들이 중복되게 선정됨 → Locality 편항이 있으며, Signal 분포가 불규칙적
- Direction 정보가 없음
- Radius=3을 고정해 사용 → Scaling 발생하는 경우 대응 불가 (멀리서 Corner로 보인 부분이 가까이에서는 아닐 수 있음)
Oriented FAST
ORB는 바로 직전에 언급한 FAST의 한계 중 상당수를 개선하려고 노력했습니다. 간단히 말하면, Scale & Rotation에 대해 Description을 추가했습니다. 우선 Scale Invariance 극복을 위해 Image Pyramid의 각 layer에서 corner detection을 수행합니다. 또한, Intensity Centroid Method를 이용해 Rotation에 대한 정보를 추가했습니다. 전반적인 프로세스는 아래와 같으며, 각각에 대해 조금 더 자세히 살펴보도록 하겠습니다.
- Key point extraction via FAST
- Select top N pixels via Harris corner detection (discard edge)
- Calculate Multi-scale key points via Image Pyramids
Image Pyramid
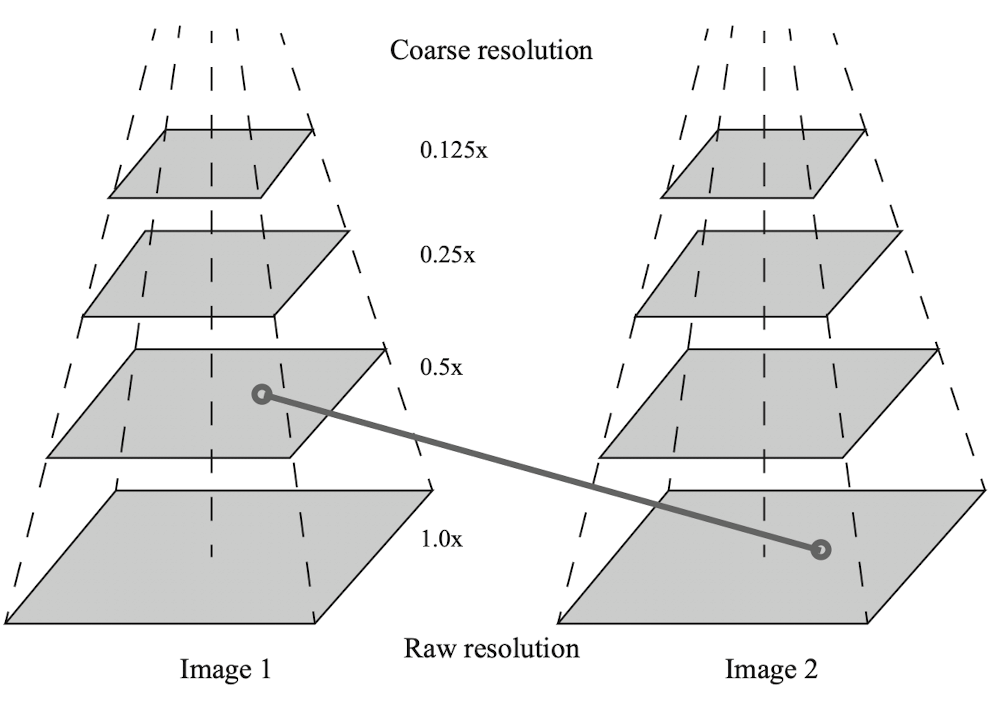
Bottom을 원본 이미지로 설정하고, 점차 coarse 하게 이미지를 쌓아갑니다. 위로 올라갈수록 멀리서 본 이미지와 같은 역할을 하는데요. 이를 통해 카메라가 앞뒤로 움직일 경우 발생하는 Scale Invariance를 해결하려 했습니다. 그림과 같이 다른 layer의 이미지와 비교하는 과정을 거치는데요. $Image 2$의 하위 layer와 $Image 1$의 상위 layer를 비교한 위 그림의 경우 현재 뒤로 이동하고 있음을 알 수 있죠.
Rotation
Rotation에 대한 정보가 없는 FAST는 회전이 발생하는 경우 key point tracking loss가 발생하기 쉽습니다. 이를 보완하기 위해 ORB는 Intensity Centroid의 모멘트를 계산해 회전에 대한 정보를 key point에 부여합니다. Intensity Centroid는 image patch에서 픽셀의 brightness와 distance값을 이용해 모멘텀을 구한 후, 이를 이용해 Centroid 값을 구하는 기법입니다. 계산 과정은 아래와 같으며, 보다 자세한 내용은 paper를 참고하시길 바랍니다 ($B$: small image block, $O$: geometric center, $C$: centroid of the image block).
$$ m_{pq}=\sum _{x,y\in B}x^py^qI(x,y),\quad p,q=\left\{0,1 \right\}$$
$$C=\left ( \frac{m_{10}}{m_{00}},\frac{m_{01}}{m_{00}} \right )$$
$$\theta=arctan(m_{01}/m_{10})$$
이렇듯 ORB는 FAST로 추출한 corner point에 Scale & Rotation에 대한 정보를 추가해 robustness를 개선합니다. 이를 Oriented FAST라고 정의하고 있습니다.
BRIEF (Binary Robust Independent Elementary Features)
BRIEF는 Binary Descriptor의 한 종류로, 연산 속도가 매우 빠르고 메모리 cost가 낮아 Real-time task와 Embedded 환경에 적합합니다. BRIEF 이전에도 SIFT/SURF 등 훌륭한 성능을 자랑하는 descriptor가 있었지만, float type 기반의 128차원 벡터를 요구했기에 연산량과 메모리 코스트 측면에서 Real-time task에 적용하기는 거의 불가능한 상황이었습니다. 이를 해결하기 위해 0, 1로만 구성된 binary descriptor가 제안되었으며, 이 새로운 알고리즘의 목표는 기존 descriptor에 대한 완벽한 저격이었습니다.
- Easy to compute(generate) via simple intensity comparison
- Easy to compare via Hamming distance
- Small binary strings via binary bit calculation
생성과 비교 연산을 최소화해 속도를 향상했으며, binary bit 연산을 이용하기 때문에 메모리 측면에서도 효율적입니다. 이제 BRIEF 알고리즘의 원리와 특징을 하나씩 살펴보도록 하겠습니다.
Algorithm
- Key point 주변에 image patch를 선정
- Patch 내에서 pixel pairs set을 random 하게 선정
- 각각의 pair에 대하여, 아래와 같이 intensity를 비교
- 모든 결괏값을 하나의 bit string으로 통합해 생성
$$b=\left\{\begin{matrix}
p>q & 1 \\
p\leq q & 0 \\
\end{matrix}\right., \quad p, q\in n_d$$
여기서 $n_d$는 Image patch에서 선정된 pixel pairs이고, $p,q$는 pair set에 해당하는 두 픽셀들입니다. 아래는 Binary descriptor에서 bit string을 생성하는 예제입니다.

Pair Selection
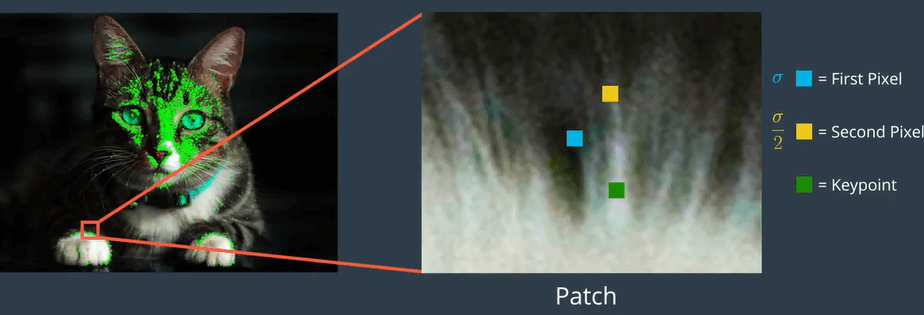
BRIEF는 key point를 중심으로 하는 image patch 내에서 두 개의 픽셀을 선정해 descriptor에 추가했습니다. 선정되는 pixel pair가 얼마나 좋게 퍼져있는지가 성능을 결정하는 주요 factor가 되는데, 이를 위해 랜덤성을 추가했습니다.
- 첫 번째 픽셀은 key point를 중심으로 하고 표준 편차가 $\sigma$인 Gaussian Distribution 내에서 선정
- 두 번째 픽셀은 key point를 중심으로 하고 표준 편차가 $2\sigma$인 Gaussian Distribution 내에서 선정 (그림에 오타 있음)
- 이 과정을 N번 반복해 N개의 bit로 이루어진 descriptor를 생성
Hamming Distance
Binary descriptor는 Hamming distance를 사용할 수 있는 강점이 있습니다. 이를 통해 descriptor 비교 연산을 매우 빠른 속도로 행할 수 있는데요. Hamming distance란 무엇일까요? 우리의 친절한 이웃, Wikipedia는 다음과 같이 Hamming distance를 소개하고 있습니다.
In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different.
사실 감이 오기 쉽지 않을 텐데요. 쉽게 말하면 두 개의 문자열, 벡터가 서로 같아지기 위해 얼마나 많은 element들이 바뀌어야 하는지를 나타낸 것입니다. 이게 Binary descriptor인 BRIEF에서는 얼마나 많은 Bit-flip이 있어야 두 개의 descriptor가 같아지는지 묻는 거죠. 아래 예제를 통해 좀 더 알아보도록 하겠습니다 (출처: Wikipedia)
- $H(1011101, 1001001) = 2$
- $H(2143896, 2233796) = 3$
- $H(toned, roses) = 3$
rBRIEF (Rotated BRIEF)
BRIEF 알고리즘에는 한 가지 문제가 있습니다. 회전이 발생할 경우 성능이 급격하게 떨어지게 되는데요. 이를 해결하기 위해 회전각에 따라 사전에 정의된 BRIEF pattern을 이용하는 방법 등이 제안되었으나, 모든 각도에 대해 pattern을 계산하는 것은 계산량이 큰 단점이 있습니다.
ORB는 이 부분을 나름의 방법으로 개선했습니다. 매번 회전에 따른 pattern을 계산하는 것보다는, BRIEF를 회전시켜 매칭되는 pattern을 찾는 방법을 제안합니다. 이를 위해 ORB는 회전에 대한 30개의 값($2\pi /30 = 12^{\circ}$ 간격)을 저장하는 LUT(Look Up Table)를 이용하고 있습니다.
기존 BRIEF에서 선정된 pair들은 적당히 큰 분산을 가지고, 평균이 0.5에 가깝게 설계되어 있습니다. ORB는 이렇게 설계된 descriptor에 rotation에 대한 보정을 해주며 분산을 더 크게 만들었으며, 이는 feature 하나하나의 분별력을 키우는 효과가 있습니다. 또한, pair의 correlation을 없애 모든 pair가 중복된 정보 없이 새로운 정보만을 사용자에게 전달하게 만들었습니다. 가능한 모든 pair에 대해서 Greedy Search를 수행하여 분산은 크고, 평균은 0.5에 가까우면서, correlation은 없는 pair들을 선정합니다. 이렇게 총 256개의 pair를 선정해 최종적으로 256bit의 descriptor를 생성합니다.
위 과정들을 통해 기존 BRIEF가 가진 rotation에 대한 취약성을 보완한 descriptor를 rBRIEF라고 합니다. 이제야 ORB의 전문인 Oriented FAST and Rotated BRIEF를 모두 알아봤습니다. Uncorrelated and high variant 한 최적의 pair들을 선정해 descriptor로서의 기능을 극대화했다고 이해하면 좋을 듯합니다.
Reference
이미지 클릭을 통해 참고한 사이트로 이동할 수 있습니다.
세 줄 요약:
- ORB는 key point detector로 FAST, descriptor로 BRIEF를 각각 개선해 적용했다.
- FAST에서 Rotation & Scale invariance, Multi-scale 개선을 통해 Robustness를 증가시켰다.
- BRIEF의 경우 uncorrelated and high variant 한 pair selection을 통해 feature 품질을 향상했으며, 회전에 대한 보정을 주어 rotation invariance를 개선했다.
Introduction
이전 게시물들을 통해 SLAM Frontend(Visual Odometry)가 무엇인지 다뤘습니다 (이전 게시물들은 Visual Odometry 태그 검색이나, [SLAM/VO] 제목 검색을 통해 보실 수 있습니다). 그중 특히 Feature based VO를 중점으로 다루며, 좋은 feature를 선정하기 위해 필요한 key point와 descriptor를 소개했습니다. 이번 시간에는 Feature Detection and Description 알고리즘 중 하나인 ORB (Oriented FAST and Rotated BRIEF)를 이야기해 볼까 합니다.
ORB란?
2011년에 ORB: an efficient alternative to SIFT or SURF 논문을 통해 처음 소개된 ORB는 현재까지도 real-time task에서 feature extraction을 위해서는 업계 포준처럼 여겨지는 알고리즘입니다. ORB의 정체를 알아보기 위해서는 우선 어떤 카테고리에 속하는 알고리즘인지 알아봐야 합니다. Harris, FAST, GFTT 등이 속한 feature detection 알고리즘일까요? 아니면 BRIEF, LBP 등이 속한 feature descriptor 알고리즘일까요?
정답은 'ORB는 스스로 다 할 수 있어요!'입니다. Feature detection을 통해 key point를 추출하고, descriptor를 계산합니다. 즉, ORB key point와 ORB descriptor 모두를 산출해 ORB feature를 최종 결과물로 내는 알고리즘입니다. 사실 이는 이름에서도 유추할 수 있는데요. Oriented FAST and Rotated BRIEF, 이름에 detector인 FAST와 descriptor인 BRIEF가 모두 들어가 있습니다. 즉, FAST로 key point를 뽑고 BRIEF로 descriptor를 계산할 거라고 광고를 하고 있는 거죠.
그렇다면 ORB는 어떤 알고리즘이라고 해야 할까요? 개인적으로는 Feature Detection and Description 알고리즘, 혹은 Feature Extraction 알고리즘이라고 생각합니다. 다만 논문을 보면 Abstract에서 저자가 다음과 같이 binary descriptor라고 정의 내리고 있으니 Descriptor로 정의 내릴 수도 있습니다 (실제로 Descriptor를 key point를 추출하는 feature detection을 포함하는 개념으로 사용하는 경우가 많습니다).
In this paper, we propose a very fast binary descriptor based on BRIEF, called ORB, which is rotation invariant and resistant to noise.
여기서 굉장히 중요한 포인트가 있는데요. 저자는 ORB의 장점을 rotation invariant와 resistant to noise로 정의했습니다. 이는 기존의 FAST와 BRIEF에서는 볼 수 없던 요소들입니다. 즉, 단순히 FAST와 BRIEF를 결합해 새로운 이름을 붙인 것이 아니라 두 알고리즘을 개선해 새로운 알고리즘을 탄생시킨 것입니다. 각각 Oriented FAST와 Rotated BRIEF로 표현된, 어떻게 보면 FAST 2.0과 BRIEF 2.0에 대해서는 우선 기존의 FAST 1.0과 BRIEF 1.0부터 살펴보고 차근차근 다루겠습니다.
FAST (Features from Accelerated Segment Test)
FAST는 2006년에 machine learning for high-speed corner detection 논문을 통해 처음 소개되었습니다. FAST는 Robotics를 포함해 활용할 수 있는 자원이 적은 환경에서 Real-time task를 수행하고자 제안되었습니다. 그렇기에 적은 연산양과 빠른 속도가 알고리즘의 가장 큰 장점이자 Contribution으로 볼 수 있습니다. FAST는 인접 pixel과 차이가 크면 Corner/Edge 등의 feature point라고 가정해 오로지 밝기 변화에만 집중했습니다. 따라서 이미지의 Grayscale 변화로만 feature를 추출합니다. 알고리즘의 전체적인 흐름은 아래와 같습니다.
- Image(
이때
for pixel in Image:
Image Patch = [16 pixels on a circle, (center = pixel, radius = 3)]
for pixel' in Image Patch:
if |Intensity(pixel) - Intensity(pixel')| > T for consecutive N pixels:
return corner
else:
continue
이렇게만 해도 key point 추출을 위해 단순 Intensity 비교만 필요하기에 FAST는 상당히 빠른 속도를 자랑합니다. 하지만 더 빠른 속도와 좀 더 괜찮은 품질의 key point를 위해 FAST는 한 걸음 더 나아갑니다. Key point candidate가 되기 위해서는 반드시 만족해야 하는 조건을 우선적으로 확인해 전체적인 계산량을 줄이고, Corner Clustering을 피하기 위해 Non-maximal Suppression을 적용했습니다.
FAST-12를 예제로 보면, 12개의 연속적인 점에서 FAST 조건을 만족할 가능성이 있는지 보기 위해서는 1, 5, 9, 13번째 pixel을 봐야 합니다. 우선 위 네 개의 점을 확인해 최소 세 점에서 만족하지 않는다면, 이 점이 corner가 될 가능성은 0이 됩니다. 이렇게 빠르게 네 점을 확인해 조건을 만족하지 않는다면, 빠르게 해당 pixel을 건너뛸 수 있습니다.
또한, FAST는 알고리즘이 단순한 만큼 Clustering 문제가 발생하게 됩니다. 이를 피하기 위해 Non-Maximal Suppression(NMS)를 적용합니다.
- Feature들이 중복되게 선정됨 → Locality 편항이 있으며, Signal 분포가 불규칙적
- Direction 정보가 없음
- Radius=3을 고정해 사용 → Scaling 발생하는 경우 대응 불가 (멀리서 Corner로 보인 부분이 가까이에서는 아닐 수 있음)
Oriented FAST
ORB는 바로 직전에 언급한 FAST의 한계 중 상당수를 개선하려고 노력했습니다. 간단히 말하면, Scale & Rotation에 대해 Description을 추가했습니다. 우선 Scale Invariance 극복을 위해 Image Pyramid의 각 layer에서 corner detection을 수행합니다. 또한, Intensity Centroid Method를 이용해 Rotation에 대한 정보를 추가했습니다. 전반적인 프로세스는 아래와 같으며, 각각에 대해 조금 더 자세히 살펴보도록 하겠습니다.
- Key point extraction via FAST
- Select top N pixels via Harris corner detection (discard edge)
- Calculate Multi-scale key points via Image Pyramids
Image Pyramid
Bottom을 원본 이미지로 설정하고, 점차 coarse 하게 이미지를 쌓아갑니다. 위로 올라갈수록 멀리서 본 이미지와 같은 역할을 하는데요. 이를 통해 카메라가 앞뒤로 움직일 경우 발생하는 Scale Invariance를 해결하려 했습니다. 그림과 같이 다른 layer의 이미지와 비교하는 과정을 거치는데요.
Rotation
Rotation에 대한 정보가 없는 FAST는 회전이 발생하는 경우 key point tracking loss가 발생하기 쉽습니다. 이를 보완하기 위해 ORB는 Intensity Centroid의 모멘트를 계산해 회전에 대한 정보를 key point에 부여합니다. Intensity Centroid는 image patch에서 픽셀의 brightness와 distance값을 이용해 모멘텀을 구한 후, 이를 이용해 Centroid 값을 구하는 기법입니다. 계산 과정은 아래와 같으며, 보다 자세한 내용은 paper를 참고하시길 바랍니다 (
이렇듯 ORB는 FAST로 추출한 corner point에 Scale & Rotation에 대한 정보를 추가해 robustness를 개선합니다. 이를 Oriented FAST라고 정의하고 있습니다.
BRIEF (Binary Robust Independent Elementary Features)
BRIEF는 Binary Descriptor의 한 종류로, 연산 속도가 매우 빠르고 메모리 cost가 낮아 Real-time task와 Embedded 환경에 적합합니다. BRIEF 이전에도 SIFT/SURF 등 훌륭한 성능을 자랑하는 descriptor가 있었지만, float type 기반의 128차원 벡터를 요구했기에 연산량과 메모리 코스트 측면에서 Real-time task에 적용하기는 거의 불가능한 상황이었습니다. 이를 해결하기 위해 0, 1로만 구성된 binary descriptor가 제안되었으며, 이 새로운 알고리즘의 목표는 기존 descriptor에 대한 완벽한 저격이었습니다.
- Easy to compute(generate) via simple intensity comparison
- Easy to compare via Hamming distance
- Small binary strings via binary bit calculation
생성과 비교 연산을 최소화해 속도를 향상했으며, binary bit 연산을 이용하기 때문에 메모리 측면에서도 효율적입니다. 이제 BRIEF 알고리즘의 원리와 특징을 하나씩 살펴보도록 하겠습니다.
Algorithm
- Key point 주변에 image patch를 선정
- Patch 내에서 pixel pairs set을 random 하게 선정
- 각각의 pair에 대하여, 아래와 같이 intensity를 비교
- 모든 결괏값을 하나의 bit string으로 통합해 생성
여기서
Pair Selection
BRIEF는 key point를 중심으로 하는 image patch 내에서 두 개의 픽셀을 선정해 descriptor에 추가했습니다. 선정되는 pixel pair가 얼마나 좋게 퍼져있는지가 성능을 결정하는 주요 factor가 되는데, 이를 위해 랜덤성을 추가했습니다.
- 첫 번째 픽셀은 key point를 중심으로 하고 표준 편차가
- 두 번째 픽셀은 key point를 중심으로 하고 표준 편차가
- 이 과정을 N번 반복해 N개의 bit로 이루어진 descriptor를 생성
Hamming Distance
Binary descriptor는 Hamming distance를 사용할 수 있는 강점이 있습니다. 이를 통해 descriptor 비교 연산을 매우 빠른 속도로 행할 수 있는데요. Hamming distance란 무엇일까요? 우리의 친절한 이웃, Wikipedia는 다음과 같이 Hamming distance를 소개하고 있습니다.
In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different.
사실 감이 오기 쉽지 않을 텐데요. 쉽게 말하면 두 개의 문자열, 벡터가 서로 같아지기 위해 얼마나 많은 element들이 바뀌어야 하는지를 나타낸 것입니다. 이게 Binary descriptor인 BRIEF에서는 얼마나 많은 Bit-flip이 있어야 두 개의 descriptor가 같아지는지 묻는 거죠. 아래 예제를 통해 좀 더 알아보도록 하겠습니다 (출처: Wikipedia)
- $H(1011101, 1001001) = 2$
- $H(2143896, 2233796) = 3$
- $H(toned, roses) = 3$
rBRIEF (Rotated BRIEF)
BRIEF 알고리즘에는 한 가지 문제가 있습니다. 회전이 발생할 경우 성능이 급격하게 떨어지게 되는데요. 이를 해결하기 위해 회전각에 따라 사전에 정의된 BRIEF pattern을 이용하는 방법 등이 제안되었으나, 모든 각도에 대해 pattern을 계산하는 것은 계산량이 큰 단점이 있습니다.
ORB는 이 부분을 나름의 방법으로 개선했습니다. 매번 회전에 따른 pattern을 계산하는 것보다는, BRIEF를 회전시켜 매칭되는 pattern을 찾는 방법을 제안합니다. 이를 위해 ORB는 회전에 대한 30개의 값(
기존 BRIEF에서 선정된 pair들은 적당히 큰 분산을 가지고, 평균이 0.5에 가깝게 설계되어 있습니다. ORB는 이렇게 설계된 descriptor에 rotation에 대한 보정을 해주며 분산을 더 크게 만들었으며, 이는 feature 하나하나의 분별력을 키우는 효과가 있습니다. 또한, pair의 correlation을 없애 모든 pair가 중복된 정보 없이 새로운 정보만을 사용자에게 전달하게 만들었습니다. 가능한 모든 pair에 대해서 Greedy Search를 수행하여 분산은 크고, 평균은 0.5에 가까우면서, correlation은 없는 pair들을 선정합니다. 이렇게 총 256개의 pair를 선정해 최종적으로 256bit의 descriptor를 생성합니다.
위 과정들을 통해 기존 BRIEF가 가진 rotation에 대한 취약성을 보완한 descriptor를 rBRIEF라고 합니다. 이제야 ORB의 전문인 Oriented FAST and Rotated BRIEF를 모두 알아봤습니다. Uncorrelated and high variant 한 최적의 pair들을 선정해 descriptor로서의 기능을 극대화했다고 이해하면 좋을 듯합니다.
Reference
이미지 클릭을 통해 참고한 사이트로 이동할 수 있습니다.