
Introduction
기존에 C언어를 사용하던 개발자는 다른 변수나 상수를 가리키기 위해서 무조건 포인터(pointer)를 사용했습니다. 그러나 포인터 문법은 어떠한 행위도 용납되는 강력한 성능에 부수적으로 따라오는 사고도 많았는데요. 이러한 휴먼 에러 발생 확률을 줄이기 위해서 C++은 포인터가 꼭 필요한 상황이 아니라면 그 기능을 한정시킬 새로운 문법을 제공합니다. 이를 참조자(레퍼런스, reference)라고 하며, 오늘은 참조자가 무엇인지, 그리고 포인터와의 차이점은 무엇인지 살펴보도록 하겠습니다.
참조자란?
우리의 친절한 이웃 위키피디아는 참조자를 아래와 같이 정의 내리고 있습니다.
In the C++ language, a reference is a simple reference datatype that is less powerful but safer than the pointer type inherited from C.
정의에서도 알 수 있듯이, 참조자는 포인터보다 덜 강력한 대신 훨씬 안전합니다. 사실 C++에서 등장한 많은 문법이 이러한 철학을 공유하고 있는데요. 너무나 강력한 대신 실수가 발생할 가능성 또한 사용자에게 떠넘긴 C의 여러 기능을 C++에서는 덜 강력한 대신 휴먼 에러 발생 확률을 현저히 낮추었습니다.
아래 예제는 포인터와 참조자의 초기화를 다루고 있습니다. 이를 통해 기본적인 참조자 활용에 대해 살펴보도록 하겠습니다.
#include <iostream>
using std::cout, std::endl;
int main()
{
int value = 5;
int *pointer = &value;
int &reference = value;
cout << “value: “ << value << endl
<< “pointer: “ << *pointer << endl
<< “reference: “ << reference << endl;
return 0;
}
value: 5
pointer: 5
reference: 5
가장 주목할 점은 * 연산자를 통해 원본값에 접근하던 포인터와 달리 레퍼런스는 선언문 외에 일반 변수와 차이점이 없다는 것입니다. 즉, 참조자를 사용한다는 말은 변수에 별명(alias)을 붙이는 것과 같은데요. 위 예제를 통해 보면 아래와 같이 해석할 수 있습니다.
int &reference = value;
참조자 선언은 기본적으로 변수 타입에 &을 붙여 나타냅니다. 이를 통해 reference는 value의 또다른 이름이라고 컴파일러에게 알려주게 됩니다. 그렇기에 참조자 변수는 코드 내에서 원본 변수의 이름으로 전부 대체해도 문제없이 코드가 돌아가게 됩니다. 이는 포인터와는 큰 차이입니다.
그러면 왜 참조자를 사용하는걸까요? C에서 포인터를 사용하는 가장 큰 이유 중 하나는 pass by pointer를 사용하기 위해서 입니다. 호출된 다른 함수에서 이전 함수의 원본을 수정하거나 복사에 걸리는 속도를 최소화하기 위해서 사용하는데요. 참조자는 포인터와 달리 원본과 같은 표기법으로 사용하는 한편, pass by reference를 지원합니다. 이는 pass by pointer와 기능적으로 완전히 동일한데요. 이는 뒤에서 자세히 살펴보도록 하겠습니다.
포인터와 참조자의 차이점
포인터와 참조자는 선언문 및 기본적인 사용법 이외에도 차이가 있습니다. 정확히는 참조자가 더 제약이 많습니다. 이는 앞에서 말했듯이 개발자가 실수할 확률을 줄여주기 위해서인데요. 크게 두 가지 제약이 있으니, 같이 살펴보도록 하겠습니다.
- 참조자는 초기화가 필수이다
포인터는 선언과 초기화가 따로 이루어져도 괜찮았습니다. 그러나 이 때문에 낭비되는 메모리가 발생하기도 하며, 여러 실수가 발생할 수 있습니다. 참조자는 이를 원천 차단하기 위해 아예 선언과 초기화가 동시에 이루어지지 않으면 에러를 뱉습니다.
int value = 5;
int &reference;
reference = value;
Declaration of reference variable ‘reference’ requires an initializer
여기에 추가로 참조자 NULL 값 초기화는 금지되어 있습니다. 편법으로 NULL 포인터를 만든 뒤, 이를 참조자가 가리키게 할 수 있지만 가능하면 사용하지 않도록 합시다. NULL 값은 항상 예상치 못한 오류를 가져올 수 있으니 말이죠 😊
- 참조자는 재할당이 불가능하다
포인터는 변수 a를 가리키다가 b로 대상을 옮기는 동작에 자유로웠습니다. 그렇기에 pass by pointer로 작성된 오픈 소스를 가져다 사용하는 도중 의도치 않게 데이터가 수정되는 사고가 많이 발생했었는데요. 참조자는 이를 원천 봉쇄했습니다. 다른 사고가 날 수는 있지만, 적어도 치명적인 메모리 손상은 피할 수 있습니다. 아래 예제는 참조자에 재할당(reassign)을 했을 때의 결과입니다.
#include <iostream>
using std::cout, std::endl;
int main()
{
int value1 = 5;
int value1 = 10;
int &reference = value1;
reference = value2;
cout << “value1: “ << value1 << endl
<< “reference: “ << reference << endl;
}
value1: 10
reference: 10
놀랍게도 참조자는 다른 변수를 가리키는 것이 아닌 현재 가리키고 있는 대상에 대한 대입 연산자를 수행합니다. 즉, 위 예제의 재할당 구문은 아래와 같이 해석될 수 있는 거죠.
value1 = value2;
참조자는 포인터 대비 제약 이외의 차이는 존재하지 않는 걸까요? 놀랍게도 참조자는 일반적인 변수와 달리 메모리 상에 존재하지 않을 수 있습니다. 일반적으로 변수는 값을 담기 위해 메모리를 할당합니다. 포인터 역시 가리킬 대상의 주소를 담을 공간을 할당받아야 하는데요. 참조자는 그런 공간이 필요할까요? 참조자는 말 그대로 변수의 또 다른 별명(alias)에 불과합니다. 그렇기에 컴파일러는 단순히 모든 참조자를 변수 명으로 대체하기만 하면 되는 것이지요. 이러한 포인터와 참조자의 메모리 상 구조 차이는 아래 그림을 통해 직관적으로 이해할 수 있습니다.
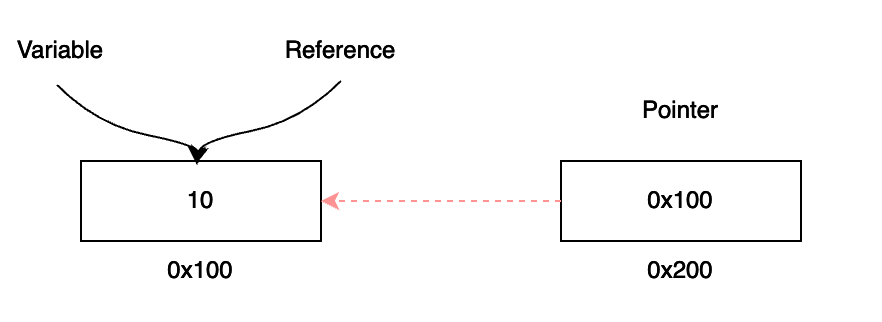
그렇다면 참조자는 모든 경우에 대해 메모리 할당이 필요 없을까요? 꼭 그렇지도 않은데요. 아래에서는 참조자도 메모리 할당이 필요한 케이스들을 살펴보도록 하겠습니다.
함수 인자로서의 참조자
모든 경우에 참조자가 메모리를 점유하지 않는 것은 아닙니다. 결론부터 말하자면, 참조자가 선언된 스코프({}) 밖에서 해당 레퍼런스가 사용될 경우 주소 전달을 위해 포인터와 같이 메모리가 할당되게 됩니다. 이에 해당하는 대표적인 예시가 함수 인자로서의 참조자 사용인데요. 함수 인자로서 참조자를 사용하게 되면, 메모리 할당 이외에도 고려할 부분이 많습니다. 아래 예제들을 통해 살펴보도록 하겠습니다.
#include <iostream>
using std::cout, std::endl;
int returnInt(int &reference)
{
cout << “[returnInt] value: “ << reference << endl
<< “[returnInt] address: “ << &reference << endl
<< endl;
}
int main()
{
int variable1 = 5;
int &reference1 = variable1;
cout << “[Main] Variable1 value: “ << variable1 << endl
<< “[Main] Variable1 address: “ << &variable1 << endl
<< endl;
cout << “[Main] Reference1 value: “ << reference1 << endl
<< “[Main] Reference1 address: “ << &reference1 << endl
<< endl;
int variable2 = returnInt(reference1);
cout << “[Main] Variable2 value: “ << variable2 << endl
<< “[Main] Variable2 address: “ << &variable2 << endl
<< endl;
return 0;
}
[Main] Variable1 value: 5
[Main] Variable1 address: 0x11b2fffb8c
[Main] Reference1 value: 5
[Main] Reference1 address: 0x11b2fffb8c
[returnInt] value: 5
[returnInt] address: 0x11b2fffb8c
[Main] Variable2 value: 5
[Main] Variable2 address: 0x11b2fffb88
출력된 로그를 보면, 참조자를 함수 인자로 전달하는 것과 메모리를 할당받는 것과의 상관관계를 전혀 알 수 없습니다. 오히려 값과 주소 모두 main 함수 내에서의 그것과 완벽히 일치해 의아한데요. 이게 어떻게 가능할까요?
개인적으로 여기에는 몇 가지 트릭이 있다고 생각합니다. 우선 스코프를 벗어난 다른 함수의 경우 콜 스택(call stack)에 구분되어 쌓이게 됩니다. 그렇기에 서로 다른 메모리를 할당받을 수밖에 없죠. 그렇기에 main 함수의 그것과 returnInt 함수의 참조자는 서로 다른 메모리를 갖고 있을 수 밖에 없습니다. 하지만 사용자에게 이러한 과정은 보여주지 않고 결과로써 나온 참조자만을 보여주고 있다고 저는 생각하는데요.
컴파일러마다 다를 수 있지만 이를 쉽게 구현하는 방법은 포인터 연산자를 활용하는 것입니다. 기본적으로 참조자가 상수 포인터(const pointer)인 만큼, 이러한 변환 과정은 어색하지 않습니다. 이를 활용해 내부적으로 변환 과정을 거치고, 사용자에게는 결과물만 보여주는 것이 하나의 테크닉일 수 있네요. 실제 구현 방법은 찾기 귀찮은 관계로 생략하지만, 아래는 포인터를 활용했을 때의 예제입니다.
#include <iostream>
using std::cout, std::endl;
int returnInt(int *pointer)
{
cout << “[returnInt] value: “ << pointer << endl
<< “[returnInt] address: “ << &pointer << endl
<< “[returnInt] real value: “ << *pointer << endl
<< endl;
}
int main()
{
int variable1 = 5;
int *pointer = &variable1;
cout << “[Main] Variable1 value: “ << variable1 << endl
<< “[Main] Variable1 address: “ << &variable1 << endl
<< endl;
cout << “[Main] Pointer value: “ << pointer << endl
<< “[Main] Pointer address: “ << &pointer << endl
<< endl;
int variable2 = returnInt(pointer);
cout << “[Main] Variable2 value: “ << variable2 << endl
<< “[Main] Variable2 address: “ << &variable2 << endl
<< endl;
return 0;
}
[Main] Variable1 value: 5
[Main] Variable1 address: 0xac79ff794
[Main] Pointer value: 0xac79ff794
[Main] Pointer address: 0xac79ff788
[returnInt] value: 0xac79ff794
[returnInt] address: 0xac79ff760
[returnInt] real value: 5
[Main] Variable2 value: 5
[Main] Variable2 address: 0xac79ff784
이렇게 pass by reference와 pass by pointer를 비교하면 동작 상의 차이는 없어 보이는데요. 그렇다면 참조자를 함수 인자로 전달하면 무슨 이점이 있을까요? 그냥 원래 알던 포인터 사용하면 안 되나요? 당연히 가능합니다. 다만, 참조자를 사용함으로써 개인적으로 느끼는 이점은 개발자가 좀 더 무지성으로 사용할 수 있다는 것입니다.
이게 무슨 헛소리냐면, pass by pointer로 구현된 오픈 소스 함수를 아무런 설명 없이 사용한다면, 이걸 주소로 전달해줘야 하는지 그냥 전달해도 되는지 알 수 없습니다. 그리고 정상적으로 동작하는지 검증도 어렵습니다. 반면에 참조자로 전달하는 경우 불필요한 &, * 연산자를 사용할 필요 없이 pass by value로 구현된 함수처럼 사용할 수 있습니다. 단적인 예시로 C언어의 scanf 함수는 포인터 기반 연산이기에 & 연산자를 필요로 했습니다. 반면에 C++의 cin 함수는 참조자 기반 연산이기에 다른 요소들을 필요로 하지 않죠.
물론 주석이 잘된 오픈 소스는 이러한 고민을 할 필요는 없겠지만, 세상에는 그렇지 않은 케이스가 많더군요. 또한, 보통 pass by pointer를 pass by reference로 설명하는 경우가 많은데 엄밀히 따지면 잘못된 설명이라고 생각합니다. C에서는 pass by reference 개념이 존재하지 않았고, 오직 pass by value만 존재했습니다. 오히려 포인터 전달의 경우 pass by value 형태로 포인터 변수를 전달한다고 보는 게 맞다고 생각합니다.
상수 참조자 (const reference)
참조자 역시 여타 다른 변수 타입들과 마찬가지로 상수(const) 선언을 지원합니다. 참조자가 가리키는 변수가 변하면 안 되는 경우에 당연히 사용 가능한데요. 이외에도 몇 가지 사용처가 있어 소개하고자 합니다.
우선 상수에 대한 참조자는 이에 맞춰 상수 참조자로 선언해야 합니다. 얼핏 보면 변수가 아닌 상수에 별명을 지어주는 게 이상할 수 있는데요. 이게 가능하다고 하니까 머리로는 이해를 해보겠는데, 도대체 왜 하는 건지 의아할 수 있습니다. 하지만 아래의 예시를 보면 이런 문법의 필요성에 공감하시리라 생각합니다.
#include <iostream>
using std::cout, std::endl;
void printNum(const int& num)
{
cout << num << endl;
}
int main()
{
printNum(5);
return 0;
}
상수 참조자로 인해 위 함수가 문제없이 돌아가게 됩니다. 만약 허용되지 않았다면, 불필요한 변수 선언을 통해 숫자를 출력해야 했을 텐데요. 이렇게 변수뿐 아니라 상수도 인자로 받기 위해서는 상수 참조자가 꼭 필요합니다.
이를 조금 더 확장해서 생각해 보면, 함수의 리턴값이 상수인 경우를 생각해 볼 수 있습니다. 혹은 지역 변수나 이를 참조하는 레퍼런스를 리턴해 리턴 후 소멸하는 경우도 고려할 수 있습니다. 만약 상수 참조자를 사용하지 않으면 어떤 문제가 발생할까요? 아래 예제를 통해 보도록 하겠습니다.
#include <iostream>
using std::cout, std::endl;
int returnInt()
{
int variable = 5;
return variable;
}
int &returnReference()
{
int variable = 5;
return variable;
}
int main()
{
int &reference1 = returnInt();
int &reference2 = returnReference();
cout << reference1 << reference2 << endl;
return 0;
}
이 경우 얼핏 보면 두 참조자 모두 5를 출력해야 할 것 같은데요. 하지만 예상과 다르게 런타임 에러를 발생시키게 됩니다. 왜 그런 걸까요? 리턴까지 마무리한 함수 데이터는 콜 스택에서 제거가 되는데요. 이때 수명을 다한 지역 변수나 참조자는 같이 휘발되게 됩니다. 결국 가리킬 대상이 없어진 reference1, reference2는 갈 길을 잃어버리고 갈팡질팡하다 뻗어버리고 말죠. 이렇게 길을 잃은 참조자들을 dangling reference라고 합니다. C언어에 익숙하신 분들은 dangling pointer를 항상 조심할 텐데요. 참조자 역시 이를 조심해야 합니다. 물론 함수 인자로 받아온 외부 참조자를 그대로 리턴하는 경우 콜 스택에 해당 주소와 참조자가 남아있기 때문에 문제없이 사용하실 수 있습니다.
참조자의 배열과 배열의 참조자
이 무슨 말장난이냐고 하실 수 있지만, 위 두 표현은 정말 다른 의미를 내포합니다. 어느 정도로 다른가 하면, 전자의 경우 문법적으로 금지되어 있으나 후자는 아무런 문제 없이 사용 가능합니다. C++ 에는 은근히 이런 게 많은데요. 이번에는 이 둘의 차이점을 살펴보도록 하겠습니다.
우선 참조자의 배열은 아래와 같이 만들기를 시도할 수 있습니다. 물론 컴파일 에러가 발생해 무슨 일이 발생하는지 확인할 수는 없지만, 금지된 동작이라는 사실은 알 수 있습니다.
int a = 5, b = 10;
int &array[2] = { a, b };
위 동작은 출력문을 쓸 필요도 없이, 아래와 같이 컴파일 에러를 뱉어줍니다.
arrays of references are illegal
참조 배열을 사용할 수 없습니다.
참조자의 배열이 금지되어 있다는 것은 이제 알겠는데, 왜 금지된 동작인 걸까요? C++의 배열은 많은 비약과 함께 간략하게 설명하면 []연산자로 원소에 접근 가능하며, 배열의 이름은 첫 번째 원소의 주소값으로 변환될 수 있어야 합니다. 그리고 *(array + 1)과 같이 포인터 연산을 통해 원소들을 접근할 수 있습니다. 이러한 포인터 연산을 참조자는 할 수 있을까요?
정답부터 말하면 불가능합니다. 앞서 말했듯이 참조자는 기본적으로 메모리 상에 존재하지 않는 경우들이 존재합니다. 이 말은 바꿔 말하면 고유 주소값이 존재하지 않으며, 배열의 포인터 연산을 참조자 배열에 적용하면 어떠한 결과를 야기할지 예측이 불가능합니다. 이러한 이유로 참조자의 참조자, 참조자 배열, 참조자의 포인터 등이 모두 언어적으로 금지되어 있습니다.
반대로 예측 가능한 배열의 참조자는 사용 가능한데요. 아래와 같이 선언 가능하며, 이를 사용하기 위해서는 반드시 배열 참조자의 크기를 명시해 줌과 동시에, 그 크기가 참조할 배열에 맞아야 합니다.
#include <iostream>
using std::cout, std::endl;
int main()
{
int array[2] = { 5, 10 };
int (&reference)[2] = array;
cout << reference[1];
}
10
참조자 사용 시 주의 사항
위에서는 참조자의 기본적인 특성에 대해서 살펴봤습니다. 값이 복사나 이를 위한 메모리 재할당이 전무하거나 미미한 참조자는 개발자에게 성능 면에서 매력적인 도구인데요. 특히 객체 지향 프로그래밍을 추구하는 C++에서 거대한 객체를 인자로 넘겨줄 때, 전체 메모리를 옮길 필요 없이, 주소 하나만 옮기면 되는 사기적인 특징을 자랑합니다. 이제 C++ 스타일로 코딩을 하며 참조자를 마구 사용하고 싶을 텐데요. 몇 가지 주의 사항만 기억하고 있으면 아주 유용하게 참조자를 활용하실 수 있을 것입니다.
- 참조자는 초기화가 필수이며, 재할당이 불가합니다. 이는 기존 포인터와의 가장 큰 차이점이니 혼용되지 않길 바랍니다.
NULL값은 참조할 수 없습니다. 물론 꼼수를 부리면NULL포인터를 참조해 만들 수는 있지만 그럴 필요가 없다면 하지 말도록 합시다.
- 참조자의 배열은 문법적으로 오류입니다. 참조자 관련해서 허용되지 않는 여러 동작이 있지만, 대표적으로는 참조자의 참조자, 참조자 배열, 그리고 참조자의 포인터가 있습니다. 배열의 참조자를 만들고 싶으면 이미 생성된 배열에 참조자들을 매칭해 주도록 합시다.
- 가변, 불가변 참조자를 구분 없이 사용하면, 오픈 소스 코드를 사용하는 개발자들에게 혼선을 줄 수 있습니다. 그러니 불가변 참조자에는
const표기를 꼭 해주길 바랍니다.
마지막으로 C++ 개발자들 사이에 유명한 말을 소개하며 마치도록 하겠습니다. 저도 스택 오버플로우에서 처음 접하고 이게 맞는 것 같다고 느낀 한 마디인데요.
Use references when you can, and pointers when you have to.
가능하면 참조자를 사용하고, 불가피한 경우에만 포인터를 사용하라는 말인데요. 이러면 개발자의 실수가 발생할 확률이 현저히 떨어지고, 프로그램의 안정성이 향상될 것입니다. 참 좋은 말이네요. 🤗
When should I use pointers instead of references in API-design?
I understand the syntax and general semantics of pointers versus references, but how should I decide when it is more-or-less appropriate to use references or pointers in an API? Naturally some situ...
stackoverflow.com
Introduction
기존에 C언어를 사용하던 개발자는 다른 변수나 상수를 가리키기 위해서 무조건 포인터(pointer)를 사용했습니다. 그러나 포인터 문법은 어떠한 행위도 용납되는 강력한 성능에 부수적으로 따라오는 사고도 많았는데요. 이러한 휴먼 에러 발생 확률을 줄이기 위해서 C++은 포인터가 꼭 필요한 상황이 아니라면 그 기능을 한정시킬 새로운 문법을 제공합니다. 이를 참조자(레퍼런스, reference)라고 하며, 오늘은 참조자가 무엇인지, 그리고 포인터와의 차이점은 무엇인지 살펴보도록 하겠습니다.
참조자란?
우리의 친절한 이웃 위키피디아는 참조자를 아래와 같이 정의 내리고 있습니다.
In the C++ language, a reference is a simple reference datatype that is less powerful but safer than the pointer type inherited from C.
정의에서도 알 수 있듯이, 참조자는 포인터보다 덜 강력한 대신 훨씬 안전합니다. 사실 C++에서 등장한 많은 문법이 이러한 철학을 공유하고 있는데요. 너무나 강력한 대신 실수가 발생할 가능성 또한 사용자에게 떠넘긴 C의 여러 기능을 C++에서는 덜 강력한 대신 휴먼 에러 발생 확률을 현저히 낮추었습니다.
아래 예제는 포인터와 참조자의 초기화를 다루고 있습니다. 이를 통해 기본적인 참조자 활용에 대해 살펴보도록 하겠습니다.
#include <iostream>
using std::cout, std::endl;
int main()
{
int value = 5;
int *pointer = &value;
int &reference = value;
cout << “value: “ << value << endl
<< “pointer: “ << *pointer << endl
<< “reference: “ << reference << endl;
return 0;
}
value: 5
pointer: 5
reference: 5
가장 주목할 점은 * 연산자를 통해 원본값에 접근하던 포인터와 달리 레퍼런스는 선언문 외에 일반 변수와 차이점이 없다는 것입니다. 즉, 참조자를 사용한다는 말은 변수에 별명(alias)을 붙이는 것과 같은데요. 위 예제를 통해 보면 아래와 같이 해석할 수 있습니다.
int &reference = value;
참조자 선언은 기본적으로 변수 타입에 &을 붙여 나타냅니다. 이를 통해 reference는 value의 또다른 이름이라고 컴파일러에게 알려주게 됩니다. 그렇기에 참조자 변수는 코드 내에서 원본 변수의 이름으로 전부 대체해도 문제없이 코드가 돌아가게 됩니다. 이는 포인터와는 큰 차이입니다.
그러면 왜 참조자를 사용하는걸까요? C에서 포인터를 사용하는 가장 큰 이유 중 하나는 pass by pointer를 사용하기 위해서 입니다. 호출된 다른 함수에서 이전 함수의 원본을 수정하거나 복사에 걸리는 속도를 최소화하기 위해서 사용하는데요. 참조자는 포인터와 달리 원본과 같은 표기법으로 사용하는 한편, pass by reference를 지원합니다. 이는 pass by pointer와 기능적으로 완전히 동일한데요. 이는 뒤에서 자세히 살펴보도록 하겠습니다.
포인터와 참조자의 차이점
포인터와 참조자는 선언문 및 기본적인 사용법 이외에도 차이가 있습니다. 정확히는 참조자가 더 제약이 많습니다. 이는 앞에서 말했듯이 개발자가 실수할 확률을 줄여주기 위해서인데요. 크게 두 가지 제약이 있으니, 같이 살펴보도록 하겠습니다.
- 참조자는 초기화가 필수이다
포인터는 선언과 초기화가 따로 이루어져도 괜찮았습니다. 그러나 이 때문에 낭비되는 메모리가 발생하기도 하며, 여러 실수가 발생할 수 있습니다. 참조자는 이를 원천 차단하기 위해 아예 선언과 초기화가 동시에 이루어지지 않으면 에러를 뱉습니다.
int value = 5;
int &reference;
reference = value;
Declaration of reference variable ‘reference’ requires an initializer
여기에 추가로 참조자 NULL 값 초기화는 금지되어 있습니다. 편법으로 NULL 포인터를 만든 뒤, 이를 참조자가 가리키게 할 수 있지만 가능하면 사용하지 않도록 합시다. NULL 값은 항상 예상치 못한 오류를 가져올 수 있으니 말이죠 😊
- 참조자는 재할당이 불가능하다
포인터는 변수 a를 가리키다가 b로 대상을 옮기는 동작에 자유로웠습니다. 그렇기에 pass by pointer로 작성된 오픈 소스를 가져다 사용하는 도중 의도치 않게 데이터가 수정되는 사고가 많이 발생했었는데요. 참조자는 이를 원천 봉쇄했습니다. 다른 사고가 날 수는 있지만, 적어도 치명적인 메모리 손상은 피할 수 있습니다. 아래 예제는 참조자에 재할당(reassign)을 했을 때의 결과입니다.
#include <iostream>
using std::cout, std::endl;
int main()
{
int value1 = 5;
int value1 = 10;
int &reference = value1;
reference = value2;
cout << “value1: “ << value1 << endl
<< “reference: “ << reference << endl;
}
value1: 10
reference: 10
놀랍게도 참조자는 다른 변수를 가리키는 것이 아닌 현재 가리키고 있는 대상에 대한 대입 연산자를 수행합니다. 즉, 위 예제의 재할당 구문은 아래와 같이 해석될 수 있는 거죠.
value1 = value2;
참조자는 포인터 대비 제약 이외의 차이는 존재하지 않는 걸까요? 놀랍게도 참조자는 일반적인 변수와 달리 메모리 상에 존재하지 않을 수 있습니다. 일반적으로 변수는 값을 담기 위해 메모리를 할당합니다. 포인터 역시 가리킬 대상의 주소를 담을 공간을 할당받아야 하는데요. 참조자는 그런 공간이 필요할까요? 참조자는 말 그대로 변수의 또 다른 별명(alias)에 불과합니다. 그렇기에 컴파일러는 단순히 모든 참조자를 변수 명으로 대체하기만 하면 되는 것이지요. 이러한 포인터와 참조자의 메모리 상 구조 차이는 아래 그림을 통해 직관적으로 이해할 수 있습니다.
그렇다면 참조자는 모든 경우에 대해 메모리 할당이 필요 없을까요? 꼭 그렇지도 않은데요. 아래에서는 참조자도 메모리 할당이 필요한 케이스들을 살펴보도록 하겠습니다.
함수 인자로서의 참조자
모든 경우에 참조자가 메모리를 점유하지 않는 것은 아닙니다. 결론부터 말하자면, 참조자가 선언된 스코프({}) 밖에서 해당 레퍼런스가 사용될 경우 주소 전달을 위해 포인터와 같이 메모리가 할당되게 됩니다. 이에 해당하는 대표적인 예시가 함수 인자로서의 참조자 사용인데요. 함수 인자로서 참조자를 사용하게 되면, 메모리 할당 이외에도 고려할 부분이 많습니다. 아래 예제들을 통해 살펴보도록 하겠습니다.
#include <iostream>
using std::cout, std::endl;
int returnInt(int &reference)
{
cout << “[returnInt] value: “ << reference << endl
<< “[returnInt] address: “ << &reference << endl
<< endl;
}
int main()
{
int variable1 = 5;
int &reference1 = variable1;
cout << “[Main] Variable1 value: “ << variable1 << endl
<< “[Main] Variable1 address: “ << &variable1 << endl
<< endl;
cout << “[Main] Reference1 value: “ << reference1 << endl
<< “[Main] Reference1 address: “ << &reference1 << endl
<< endl;
int variable2 = returnInt(reference1);
cout << “[Main] Variable2 value: “ << variable2 << endl
<< “[Main] Variable2 address: “ << &variable2 << endl
<< endl;
return 0;
}
[Main] Variable1 value: 5
[Main] Variable1 address: 0x11b2fffb8c
[Main] Reference1 value: 5
[Main] Reference1 address: 0x11b2fffb8c
[returnInt] value: 5
[returnInt] address: 0x11b2fffb8c
[Main] Variable2 value: 5
[Main] Variable2 address: 0x11b2fffb88
출력된 로그를 보면, 참조자를 함수 인자로 전달하는 것과 메모리를 할당받는 것과의 상관관계를 전혀 알 수 없습니다. 오히려 값과 주소 모두 main 함수 내에서의 그것과 완벽히 일치해 의아한데요. 이게 어떻게 가능할까요?
개인적으로 여기에는 몇 가지 트릭이 있다고 생각합니다. 우선 스코프를 벗어난 다른 함수의 경우 콜 스택(call stack)에 구분되어 쌓이게 됩니다. 그렇기에 서로 다른 메모리를 할당받을 수밖에 없죠. 그렇기에 main 함수의 그것과 returnInt 함수의 참조자는 서로 다른 메모리를 갖고 있을 수 밖에 없습니다. 하지만 사용자에게 이러한 과정은 보여주지 않고 결과로써 나온 참조자만을 보여주고 있다고 저는 생각하는데요.
컴파일러마다 다를 수 있지만 이를 쉽게 구현하는 방법은 포인터 연산자를 활용하는 것입니다. 기본적으로 참조자가 상수 포인터(const pointer)인 만큼, 이러한 변환 과정은 어색하지 않습니다. 이를 활용해 내부적으로 변환 과정을 거치고, 사용자에게는 결과물만 보여주는 것이 하나의 테크닉일 수 있네요. 실제 구현 방법은 찾기 귀찮은 관계로 생략하지만, 아래는 포인터를 활용했을 때의 예제입니다.
#include <iostream>
using std::cout, std::endl;
int returnInt(int *pointer)
{
cout << “[returnInt] value: “ << pointer << endl
<< “[returnInt] address: “ << &pointer << endl
<< “[returnInt] real value: “ << *pointer << endl
<< endl;
}
int main()
{
int variable1 = 5;
int *pointer = &variable1;
cout << “[Main] Variable1 value: “ << variable1 << endl
<< “[Main] Variable1 address: “ << &variable1 << endl
<< endl;
cout << “[Main] Pointer value: “ << pointer << endl
<< “[Main] Pointer address: “ << &pointer << endl
<< endl;
int variable2 = returnInt(pointer);
cout << “[Main] Variable2 value: “ << variable2 << endl
<< “[Main] Variable2 address: “ << &variable2 << endl
<< endl;
return 0;
}
[Main] Variable1 value: 5
[Main] Variable1 address: 0xac79ff794
[Main] Pointer value: 0xac79ff794
[Main] Pointer address: 0xac79ff788
[returnInt] value: 0xac79ff794
[returnInt] address: 0xac79ff760
[returnInt] real value: 5
[Main] Variable2 value: 5
[Main] Variable2 address: 0xac79ff784
이렇게 pass by reference와 pass by pointer를 비교하면 동작 상의 차이는 없어 보이는데요. 그렇다면 참조자를 함수 인자로 전달하면 무슨 이점이 있을까요? 그냥 원래 알던 포인터 사용하면 안 되나요? 당연히 가능합니다. 다만, 참조자를 사용함으로써 개인적으로 느끼는 이점은 개발자가 좀 더 무지성으로 사용할 수 있다는 것입니다.
이게 무슨 헛소리냐면, pass by pointer로 구현된 오픈 소스 함수를 아무런 설명 없이 사용한다면, 이걸 주소로 전달해줘야 하는지 그냥 전달해도 되는지 알 수 없습니다. 그리고 정상적으로 동작하는지 검증도 어렵습니다. 반면에 참조자로 전달하는 경우 불필요한 &, * 연산자를 사용할 필요 없이 pass by value로 구현된 함수처럼 사용할 수 있습니다. 단적인 예시로 C언어의 scanf 함수는 포인터 기반 연산이기에 & 연산자를 필요로 했습니다. 반면에 C++의 cin 함수는 참조자 기반 연산이기에 다른 요소들을 필요로 하지 않죠.
물론 주석이 잘된 오픈 소스는 이러한 고민을 할 필요는 없겠지만, 세상에는 그렇지 않은 케이스가 많더군요. 또한, 보통 pass by pointer를 pass by reference로 설명하는 경우가 많은데 엄밀히 따지면 잘못된 설명이라고 생각합니다. C에서는 pass by reference 개념이 존재하지 않았고, 오직 pass by value만 존재했습니다. 오히려 포인터 전달의 경우 pass by value 형태로 포인터 변수를 전달한다고 보는 게 맞다고 생각합니다.
상수 참조자 (const reference)
참조자 역시 여타 다른 변수 타입들과 마찬가지로 상수(const) 선언을 지원합니다. 참조자가 가리키는 변수가 변하면 안 되는 경우에 당연히 사용 가능한데요. 이외에도 몇 가지 사용처가 있어 소개하고자 합니다.
우선 상수에 대한 참조자는 이에 맞춰 상수 참조자로 선언해야 합니다. 얼핏 보면 변수가 아닌 상수에 별명을 지어주는 게 이상할 수 있는데요. 이게 가능하다고 하니까 머리로는 이해를 해보겠는데, 도대체 왜 하는 건지 의아할 수 있습니다. 하지만 아래의 예시를 보면 이런 문법의 필요성에 공감하시리라 생각합니다.
#include <iostream>
using std::cout, std::endl;
void printNum(const int& num)
{
cout << num << endl;
}
int main()
{
printNum(5);
return 0;
}
상수 참조자로 인해 위 함수가 문제없이 돌아가게 됩니다. 만약 허용되지 않았다면, 불필요한 변수 선언을 통해 숫자를 출력해야 했을 텐데요. 이렇게 변수뿐 아니라 상수도 인자로 받기 위해서는 상수 참조자가 꼭 필요합니다.
이를 조금 더 확장해서 생각해 보면, 함수의 리턴값이 상수인 경우를 생각해 볼 수 있습니다. 혹은 지역 변수나 이를 참조하는 레퍼런스를 리턴해 리턴 후 소멸하는 경우도 고려할 수 있습니다. 만약 상수 참조자를 사용하지 않으면 어떤 문제가 발생할까요? 아래 예제를 통해 보도록 하겠습니다.
#include <iostream>
using std::cout, std::endl;
int returnInt()
{
int variable = 5;
return variable;
}
int &returnReference()
{
int variable = 5;
return variable;
}
int main()
{
int &reference1 = returnInt();
int &reference2 = returnReference();
cout << reference1 << reference2 << endl;
return 0;
}
이 경우 얼핏 보면 두 참조자 모두 5를 출력해야 할 것 같은데요. 하지만 예상과 다르게 런타임 에러를 발생시키게 됩니다. 왜 그런 걸까요? 리턴까지 마무리한 함수 데이터는 콜 스택에서 제거가 되는데요. 이때 수명을 다한 지역 변수나 참조자는 같이 휘발되게 됩니다. 결국 가리킬 대상이 없어진 reference1, reference2는 갈 길을 잃어버리고 갈팡질팡하다 뻗어버리고 말죠. 이렇게 길을 잃은 참조자들을 dangling reference라고 합니다. C언어에 익숙하신 분들은 dangling pointer를 항상 조심할 텐데요. 참조자 역시 이를 조심해야 합니다. 물론 함수 인자로 받아온 외부 참조자를 그대로 리턴하는 경우 콜 스택에 해당 주소와 참조자가 남아있기 때문에 문제없이 사용하실 수 있습니다.
참조자의 배열과 배열의 참조자
이 무슨 말장난이냐고 하실 수 있지만, 위 두 표현은 정말 다른 의미를 내포합니다. 어느 정도로 다른가 하면, 전자의 경우 문법적으로 금지되어 있으나 후자는 아무런 문제 없이 사용 가능합니다. C++ 에는 은근히 이런 게 많은데요. 이번에는 이 둘의 차이점을 살펴보도록 하겠습니다.
우선 참조자의 배열은 아래와 같이 만들기를 시도할 수 있습니다. 물론 컴파일 에러가 발생해 무슨 일이 발생하는지 확인할 수는 없지만, 금지된 동작이라는 사실은 알 수 있습니다.
int a = 5, b = 10;
int &array[2] = { a, b };
위 동작은 출력문을 쓸 필요도 없이, 아래와 같이 컴파일 에러를 뱉어줍니다.
arrays of references are illegal
참조 배열을 사용할 수 없습니다.
참조자의 배열이 금지되어 있다는 것은 이제 알겠는데, 왜 금지된 동작인 걸까요? C++의 배열은 많은 비약과 함께 간략하게 설명하면 []연산자로 원소에 접근 가능하며, 배열의 이름은 첫 번째 원소의 주소값으로 변환될 수 있어야 합니다. 그리고 *(array + 1)과 같이 포인터 연산을 통해 원소들을 접근할 수 있습니다. 이러한 포인터 연산을 참조자는 할 수 있을까요?
정답부터 말하면 불가능합니다. 앞서 말했듯이 참조자는 기본적으로 메모리 상에 존재하지 않는 경우들이 존재합니다. 이 말은 바꿔 말하면 고유 주소값이 존재하지 않으며, 배열의 포인터 연산을 참조자 배열에 적용하면 어떠한 결과를 야기할지 예측이 불가능합니다. 이러한 이유로 참조자의 참조자, 참조자 배열, 참조자의 포인터 등이 모두 언어적으로 금지되어 있습니다.
반대로 예측 가능한 배열의 참조자는 사용 가능한데요. 아래와 같이 선언 가능하며, 이를 사용하기 위해서는 반드시 배열 참조자의 크기를 명시해 줌과 동시에, 그 크기가 참조할 배열에 맞아야 합니다.
#include <iostream>
using std::cout, std::endl;
int main()
{
int array[2] = { 5, 10 };
int (&reference)[2] = array;
cout << reference[1];
}
10
참조자 사용 시 주의 사항
위에서는 참조자의 기본적인 특성에 대해서 살펴봤습니다. 값이 복사나 이를 위한 메모리 재할당이 전무하거나 미미한 참조자는 개발자에게 성능 면에서 매력적인 도구인데요. 특히 객체 지향 프로그래밍을 추구하는 C++에서 거대한 객체를 인자로 넘겨줄 때, 전체 메모리를 옮길 필요 없이, 주소 하나만 옮기면 되는 사기적인 특징을 자랑합니다. 이제 C++ 스타일로 코딩을 하며 참조자를 마구 사용하고 싶을 텐데요. 몇 가지 주의 사항만 기억하고 있으면 아주 유용하게 참조자를 활용하실 수 있을 것입니다.
- 참조자는 초기화가 필수이며, 재할당이 불가합니다. 이는 기존 포인터와의 가장 큰 차이점이니 혼용되지 않길 바랍니다.
NULL값은 참조할 수 없습니다. 물론 꼼수를 부리면NULL포인터를 참조해 만들 수는 있지만 그럴 필요가 없다면 하지 말도록 합시다.
- 참조자의 배열은 문법적으로 오류입니다. 참조자 관련해서 허용되지 않는 여러 동작이 있지만, 대표적으로는 참조자의 참조자, 참조자 배열, 그리고 참조자의 포인터가 있습니다. 배열의 참조자를 만들고 싶으면 이미 생성된 배열에 참조자들을 매칭해 주도록 합시다.
- 가변, 불가변 참조자를 구분 없이 사용하면, 오픈 소스 코드를 사용하는 개발자들에게 혼선을 줄 수 있습니다. 그러니 불가변 참조자에는
const표기를 꼭 해주길 바랍니다.
마지막으로 C++ 개발자들 사이에 유명한 말을 소개하며 마치도록 하겠습니다. 저도 스택 오버플로우에서 처음 접하고 이게 맞는 것 같다고 느낀 한 마디인데요.
Use references when you can, and pointers when you have to.
가능하면 참조자를 사용하고, 불가피한 경우에만 포인터를 사용하라는 말인데요. 이러면 개발자의 실수가 발생할 확률이 현저히 떨어지고, 프로그램의 안정성이 향상될 것입니다. 참 좋은 말이네요. 🤗
When should I use pointers instead of references in API-design?
I understand the syntax and general semantics of pointers versus references, but how should I decide when it is more-or-less appropriate to use references or pointers in an API? Naturally some situ...
stackoverflow.com